Ethereum Under the Hood- Part 2 (RLP Encoding)
Part-2 of the article, if you have not gone through Part-1, please do. We will cover how Ethereum uses Recursive Length Prefix to encode data and state in this article.
This is a slightly longer read, so get yourself some coffee and be prepared to get confused, I did reading about RLP
The Problem:
Ethereum is a global computer and data to be processed by Ethereum has to be sent across the wire compactly and efficiently. Ethereum team chose Recursive Link Prefix decoding/encoding algorithm to achieve the above-stated goals. If you go through articles on Ethereum there are references to the “stack machines” and its usage in Ethereum, so let’s cover them for a little bit.
The Stack Machine:
Let’s briefly touch on what is a Stack
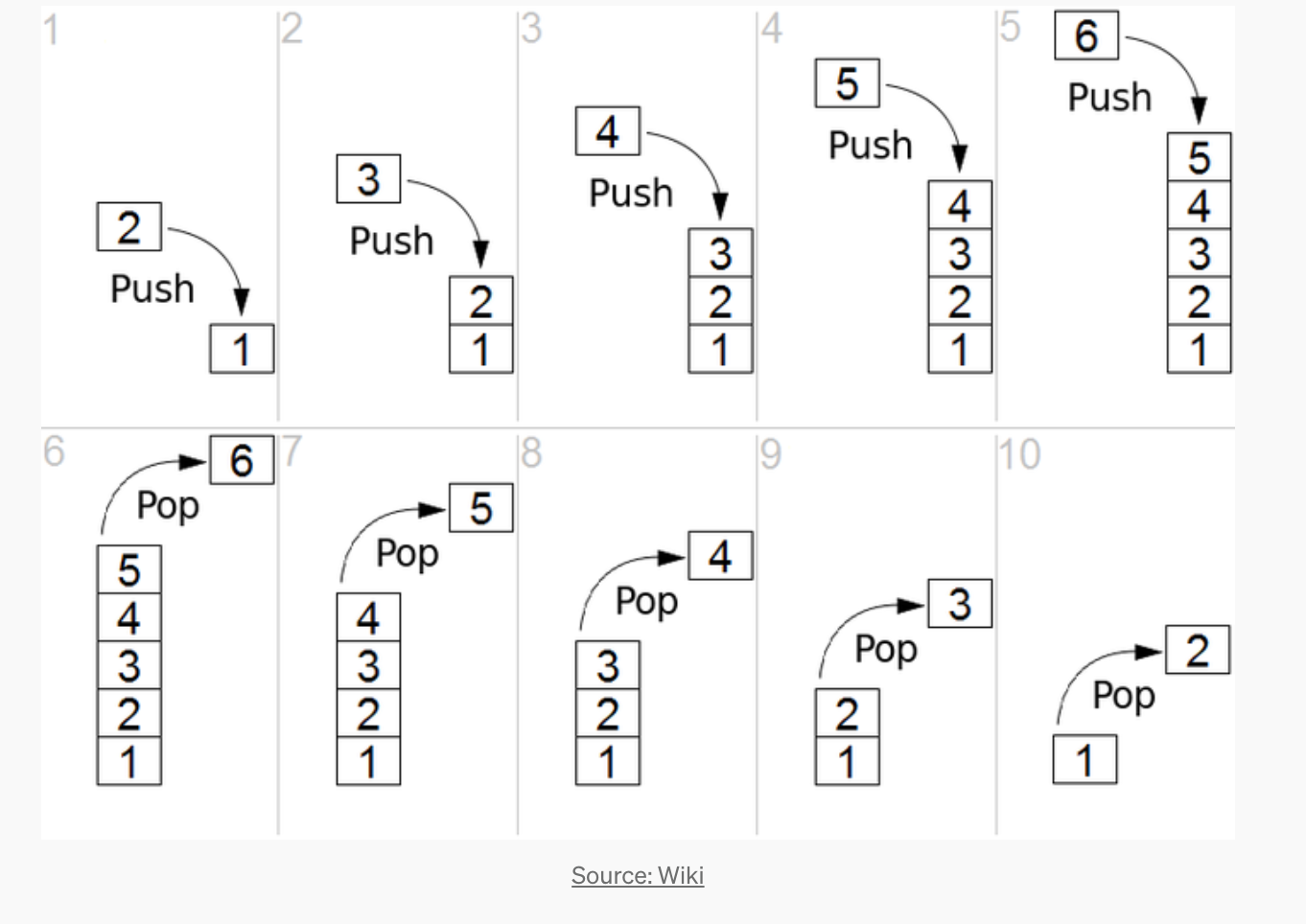
The Ethereum Virtual Machine(EVM) is a Stack-based machine that stores instructions and data in a stack-based using the LIFO(Last In First Out) method. Let’s take the example of a string “cat” and see how it’s pushed into a stack

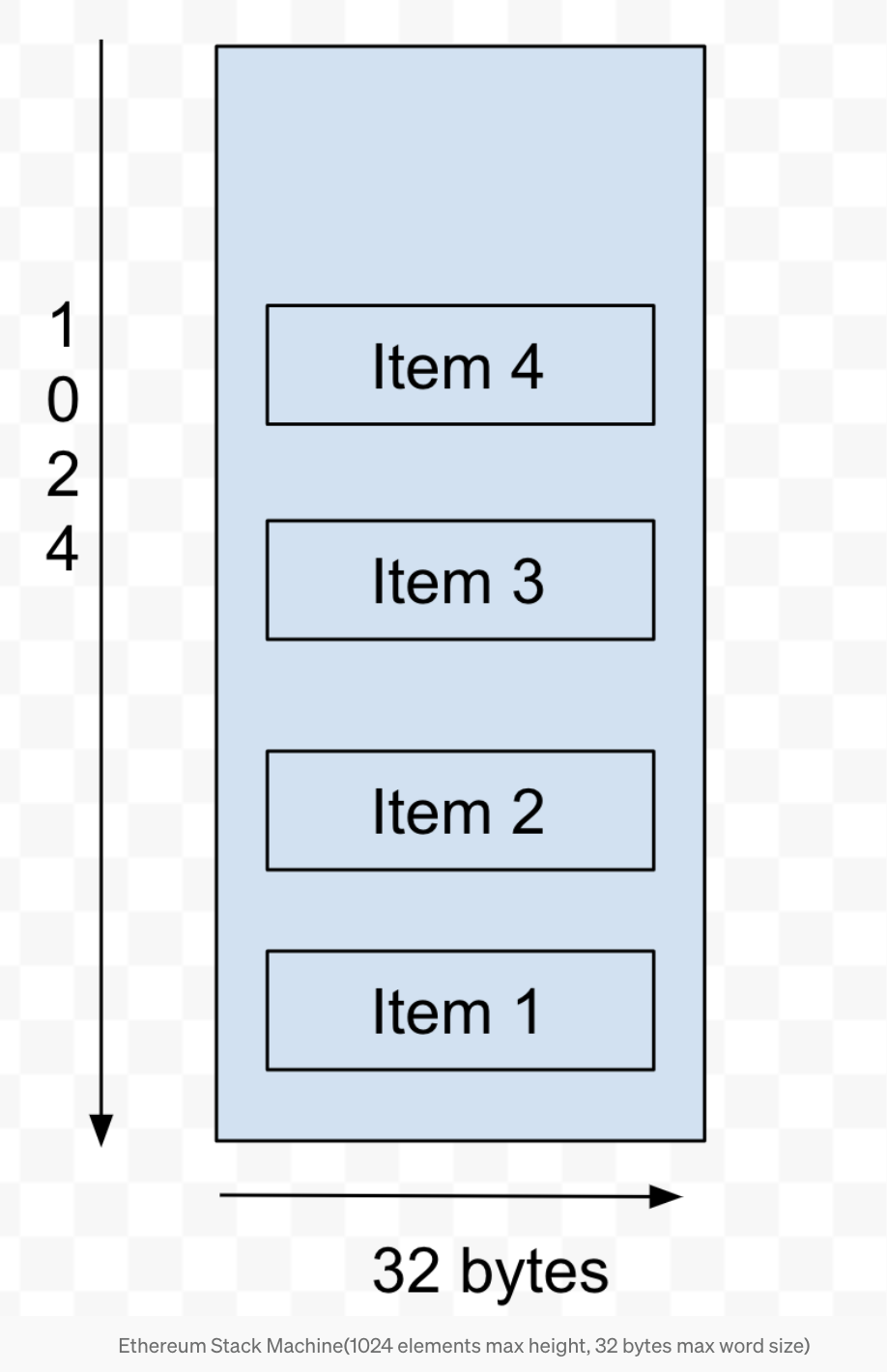
Ethereum Stack has certain restrictions. The Stack depth is maxed out at 1024 elements, and max word size per instruction is 256 bits or a max of 32 bytes. I think of this as how broad the instruction set can be, as depicted in the diagram below.
Stack Machines are ideal to have a mini-compiler implemented. Let’s take an expression
[[0x12344],[ (a+b*c/d), 'x', 9] ]
A couple of things to consider, there are two items on the above array. A hex value and expression. Think of hex value (0x12344) as an Ethereum address and the expression as the state change information. Note that the max size of the word is 256 bits. Let’s consider[(a+b*c/d), ‘x’, 9 ]. The whole expression is less than 32 bytes. Why 32 bytes you ask? Here is a good stack exchange discussion on that topic. Check out this youtube video about Stack Machines
Examples of items and items
- “Bitcoin”
- [ [] ]
- [ “Lion” ]
- [ [ “cat”, 123, ‘d’, ‘o’, ‘g’] ]
Now, what is Recursive Link Prefix (RLP)?
RLP is a set of rules to encode and decode structures and data. Part II. I focus on RLP encoding; we will cover RLP decoding in part II.II of the article in later posts. Let us recap what’s inside of an RLP. If you recall in the previous article we discussed “items”, all “items” are byte-arrays. RLP function accepts one parameter of the type object.
A critical aspect of RLP is that it leaves encoding rules of specific structure to the top-level layers, for example, if there is another structure, e.g. {“abc” }. RLP will consider this as a string element and will leave the encoding to the top-level layers

Let’s get into those RLP encoding rules for these objects :
Tip: I would suggest opening up an ASCII chart.
RLP encoding rules are defined as follows:
Rule 1: When encoding a payload with 1 byte and value in that byte falls within the following range [0x00, 0x7f], in other words within [0, 127] then encode the single-byte as RLP itself

so encoding 120 into RLP results in 78 and 127 results in 7F, and for “a”, encoding results in “a” and the byte size is 1, and encoding rule#1 applies.
Rule 2: When encoding a string (in byte array) that falls between 0 and 55 bytes apply the following logic.
0x80+length(string),string
string "dog" to byte-array in hex is [0x64,0x6f,0x67] and size of the byte array is 3Let us encode item “dog” into RLP, the size aka length of byte array is 3, so encoding into RLP will result in
[0x80+3,0x64,0x6f,0x67] -> [0x83, 0x64, 0x6f, 0x67]
e.g.: Another example would be “hello world” of RLP encoding. The size of “hello world” is 11 bytes.
$ "hello world" to rlp [0x8B 0x68 0x65 0x6C 0x6C 0x6F 0x20 0x77 0x6F 0x72 0x6C 0x64]Rule 3: When encoding a string (in byte array) greater than 55 bytes apply the following rule.
1)0xb7+length_in_bytes(byte_size(string))
2)length(string)
3)encoded string
Join 1,2,3Let’s take an example string “Hello there, I am a very very long string, and I am going get encoded in RLP!”. The length of the string is 76, so rule 3 applies. Let’s get a couple of prereqs out of the way.
a)len raw string = 76
b)byte_size(string) =76
c)length_in_bytes(byte_size(string) ) = 1Following the steps laid out by rule#3
- 0xb7 + 1
- 76
- “Hello there, I am a very very long string, and I am going get encoded in RLP!”
- (0xb7+1) , 76, “Hello there, I am a very very long string, and I am going get encoded in RLP!”
So the final RLP encoding in hex is:
B84C48656C6C6F2074686572652C204920616D206120766572792076657279206C6F6E6720737472696E6720616E64204920616D20676F696E672067657420656E636F64656420696E20524C5021
Rule 4: When encoding a list and the encoded payload in the list is between 0–55 bytes apply the following encoding rule.
1)0xc0+length of (list))
2)Encoded string
Join 1,2Given an input to RLP encoding with [“dog”, “mouse”, “tigers”, 127]
We need to encode the payload within the list first.
- “dog” : 0x83, 0x64, 0x6F, 0x67
- “mouse” : 0x85 ,0x6D, 0x6F ,0x75, 0x73, 0x65
- “tigers” : 0x86, 0x74 ,0x69 ,0x67 ,0x65 ,0x72 ,0x73
- 127 : 0x7F
Now the list with the encoded payload looks like this:
[ 0x83 0x64 0x6F 0x67 0x85 0x6D 0x6F 0x75 0x73 0x65 0x86 0x74 0x69 0x67 0x65 0x72 0x73 0x7F ] and the length of the list is 18(12 in hex)
Rule 5 : When encoding a list and the encoded payload in the list is greater than 55 bytes apply the following encoding rule.
1)0xf7+length_in_bytes(item 2)
2)length(payload)
3)Encoded payload
Join 1,2,3I would let you do the rest, very similar to the rule above.
Finally a couple of notes
- RLP encodes positive integers in Big Endian format, and discards the leading zeros, and integer value zero is the same as an empty byte array.
- There are certain constants for empty lists, string, and integer 0
1) Empty List [] encoded to 0xC0
2) Empty String "" encoded to 0x80
3) Integer 0 encoded to 0x80Recap Recap Recap
My recommendation is to let this digest and come back to the article again. I am not 100% sure on some of the finer details either, but I did get some useful perspectives on the design decision and some fantastic help from the good folks at stack-exchange.
Let’s recap:
- RLP is a set of rules to encode an item or a list of items.
- RLP has a different set of rules based on the size of the payload.
- Strings is a byte array.
- Empty strings, lists have a predefined value.
- RLP is used due to its capability to compact data and is simple.
Tip: Try reading the rationale on the design decisions on why the Ethereum team choose RLP. There are various implementations of RLP. I would recommend going through them. I did refer to implementation in Elixir and Ruby
There are also other great medium posts on RLP which I entirely referred to go and will continue to do for future reference. Check out my implementation with some help of code snippets from girishramnani, and many thanks to @kvkalidindi for proofreading and valuable comments.
References
 Maran Hidskes
Maran Hidskes
